# SLaM @NDW
Wilkommen zum virtuellen Stand des SLaM Labs!

# Auf dieser Seite können Sie die Themen
# nachlesen, die auf der Langen Nacht der
# Wissenschaft an unserem Stand vorgetragen
# wurden. # Navigieren Sie die Website indem Sie den > # Pfeilen > folgen > # Im Landschaftsmodus ist diese Website hübscher
# SLaM @NDW
Wilkommen zum virtuellen Stand des SLaM Labs!Bevor wir zu den vorgestellten Postern kommen, hier noch die Erfahrungsberichte unserer Studentinnen und Studenten:
Wir haben unsere Studierenden und studentischen Hilfskräfte gefragt, wie sie ihre Arbeit in der Forschung erleben und welche Erfahrungen sie dabei sammeln konnten.



Erfahrungsberichte unserer Studentinnen und Studenten:
# SLaM @NDW


Erfahrungsberichte unserer Studentinnen und Studenten:
# SLaM @NDW


Erfahrungsberichte unserer Studentinnen und Studenten:
# SLaM @NDW


Erfahrungsberichte unserer Studentinnen und Studenten:
# SLaM @NDW


Erfahrungsberichte unserer Studentinnen und Studenten:
# SLaM @NDW


Erfahrungsberichte unserer Studentinnen und Studenten:
# SLaM @NDW
Erfahrungsberichte unserer Studentinnen und Studenten:


# SLaM @NDW

Erfahrungsberichte unserer Studentinnen und Studenten:
# SLaM @NDW
Navigation# Thema auswählen
>>>
# Navigation
# oder weitere
# Themen stöbern
# Vortrag 1
Was ist Phonetik und
wozu das Labor?



# Vortrag 1
PhonetikPhonetik ist die Studie der Produktion, der Perzeption und der akustischen Eigenschaften von Sprachlauten. Zur Untersuchung von Sprachlauten werden Sprachaufnahmen in digitaler Form benötigt. Diese lassen sich heutzutage prinzipiell überall anfertigen, aber ein Phonetiklabor ist speziell darauf ausgerichtet, klare und hochqualitative Aufnahmen anzufertigen, indem beispielsweise Störgeräusche vermieden werden und spezielles Equipment genutzt wird.
# Vortrag 1
Lerne praktische Laborfertigkeiten
der Phonetik: Ein interaktives
Erlebnis aus der Ich-Perspektive
Neue Skills lernt man oft am besten, indem man aktiv daran arbeitet und dabei darüber nachdenkt, was man tut. Im Online-Moodle-Kurs habt Ihr Möglichkeit, unser Phonetiklabor von zu Hause aus zu erleben und auszuprobieren, ohne dass eine zeitliche oder räumliche Grenze besteht. Die Inhalte sind flexibel und können im eigenen Tempo bearbeitet werden.
Die Lerneinheiten sind in zwei Hauptbereiche unterteilt:

▶ Aufnehmen von Sprachdaten (1):
▷ Grundlagen eines einfachen Sprachproduktionsexperiments im Labor einschließlich Ausrüstung, Aufbau, Ablauf und Laboretikette
▷ Regeln für ein gutes Datenmanagement
# Vortrag 1

▶ Auswerten und Präsentieren von
Sprachdaten (2):
▷ Grundanwendungen von Analyse und Statistikprogrammen wie TextGrid, Praat und R
▷ Visualisierung von Daten mittelsggplot, eine Anwendung zur Veranschaulichung der gesammelten Daten und Zusammenhänge
# Vortrag 1
# Vortrag 1
▶ Der Kurs ist für alle registrierten Nutzer jederzeit online über Moodle verfügbar
▶ Die Lerneinheiten bestehen aus informativen Leseeinheiten und Quizzes unterschiedlicher Formate, um den persönlichen Lernprozess auf spielerische Weise beurteilen zu können

▶ Bildunterstützte, interaktive Schritt-für-Schritt-Anleitungen ermöglichen ein sicheres Arbeiten mit den genannten Programmen und vermitteln einige Grundfertigkeiten
des wissenschaftlichen Arbeitens, die auch über den Bereich der Phonetik hinaus relevant sind
# Vortrag 1

▶ Sowohl die Leseeinheiten als auch die Quizzes werden in verschiedenen Formaten zur Verfügung gestellt:
▷ Interaktiver 360-Grad-Rundgang durch das Labor mit vielen Elementen, die angeklickt werden können, um zusätzliche Informationen zu den jeweiligen Geräten zu erhalten
▷ Equipment kann virtuell für ein einfaches Sprachproduktions-Experiment aufgebaut werden
▷ Störgeräusche-Quiz: Hier können mögliche Störgeräusche ihrer jeweiligen Quelle zugeordnet werden
# Vortrag 1
# Vortrag 1
▶ Narrative Rahmenhandlung entfaltet sich über mehrere in die Lerneinheiten integrierte kurze Filmsequenzen
▶ Teilnehmende können sich in die Protagonisten einfühlen und gemeinsam mit ihnen die Lernziele erreichen
# Vortrag 1
Obwohl die ursprüngliche Idee des Kurses lediglich darin bestand, allen interessierten Lernenden einen einfachen Zugang zum Phonetiklabor zu bieten, ist dieser nun nicht nur darauf ausgerichtet, phonetische Skills zu verbessern, sondern Lernende aller Niveaus bei der Planung und Durchführung von Experimenten zu unterstützen, die Daten und Zusammenhänge in angemessener Weise zu präsentieren und fundierte Kenntnisse darüber zu erwerben, wie man qualitativ hochwertige Ergebnisse in Bezug auf Zuverlässigkeit, Reproduzierbarkeit und Validität als Grundlage für gute wissenschaftliche Arbeit erzielt.
# link to the project: https://slam.phil.hhu.de/projects/elff_phonetics_adventure/
# Vortrag 1Danksagungen
Unser herzlicher Dank gilt dem E-Learning Förderfonds für die Unterstützung des Projektarchiv-Projekts. Durch Ihre Förderung konnten wir innovative E-Learning-Lösungen entwickeln und die digitale Bildung nachhaltig verbessern.
Vielen Dank!

Navigation
# Themenblock anklicken um
# ihn auszuwählenWas ist Phonetik und wozu das Labor? Ein interaktives Erlebnis aus der Ich-Perspektive
# Navigation
# Vortrag 2
EinleitungParkinson-Krankheit:
▶ Neurologische Erkrankung
▶ Ursache: Absterben von Nervenzellen im Gehirn
▶ Symptome: Zittern, Muskelsteifheit, Gleichgewichtsstörungen, Sprachstörungen
▶ Überwiegend sind ältere Menschen betroffen
▶ Unheilbar
EinleitungParkinson-Krankheit:
▶ Eine frühzeitige Diagnose kann dazu beitragen, das Fortschreiten der Krankheit und die Behandlung zu kontrollieren.
▶ Für die Frühdiagnose verwenden mehrere Studien Sprachaufnahmen, insbesondere der Vokalproduktion, um Patienten mit Anzeichen von Pakinson zu erkennen
# Vortrag 2
# Vortrag 2
EinleitungForschungsfragen
In Studien zur Früherkennung von Parkinson im Zeitraum von 2013 bis 2023:
1) Gibt es ein Ungleichgewicht in der Anzahl der Teilnehmer (Stichprobengröße) zwischen der Parkinson-Gruppe und der gesunden Gruppe?
# Vortrag 2
EinleitungForschungsfragen
In Studien zur Früherkennung von Parkinson im Zeitraum von 2013 bis 2023:
2) Wenn ja, wird dies in den Studien berücksichtigt?
# Vortrag 2
EinleitungForschungsfragen
In Studien zur Früherkennung von Parkinson im Zeitraum von 2013 bis 2023:
3) Wirkt sich das Ungleichgewicht auf die Klassifizierungsgenauigkeit der Merkmale aus, die aus der Vokalproduktion der beiden Gruppen extrahiert wurden?
# Vortrag 2
Termini
Ein systematischer Überblick (Uman 2011)
Detaillierter Plan & Suchstrategie zur Verringerung von Verzerrungen (3 Schritte):
1) Identifizierung
2) Bewertung
3) Zusammenfassung aller relevanten Studien zu einem bestimmten Thema
Stichprobengröße (Lakens 2022)
Anzahl der in eine Studie einbezogenen Teilnehmer
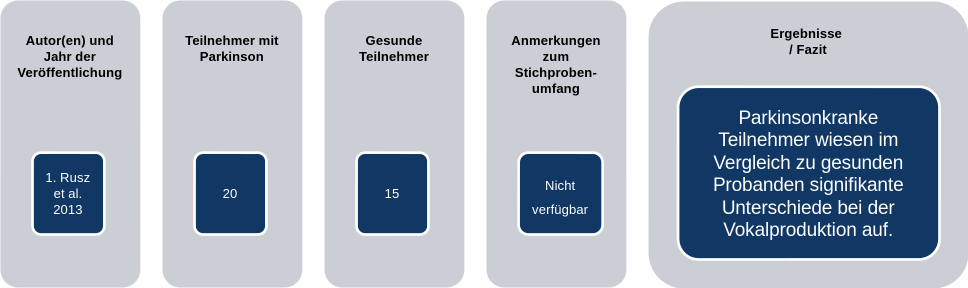
Erkennung von Parkinson (Rusz 2013 et al.)
Analyse von Sprache, die von Parkinson-Kranken und Gesunden produziert wird, um Patienten mit Anzeichen der Krankheit zu identifizieren
# Vortrag 2
Termini
▶ Vokalproduktion
Vokalproduktion: Sage den Vokal /a/ in 5 Sekunden.
▶ Sprachliche Biomarker (Martínez-Nicolas et al. 2022)
Biologische Merkmale der Stimme, die gemessen und bewertet werden, um festzustellen, ob eine Krankheit vorhanden ist oder wie sie bei einer Person fortgeschritten ist.
# Vortrag 2
Vorangegangene Studien (Ngo et al. 2022)
▶ Thema
Computergestützte Analyse von Sprache und Stimme zur Erkennung von Parkinson und Überwachung
▶ Methode
PRISMA-Richtlinien mit Kriterien
(i) Relevante Studien im Zeitraum 2010-2021;
(ii) In englischer Sprache veröffentlicht;
(iii) Veröffentlicht in Fachzeitschriften mit Peer-Review
▶ Ergebnisse
Sprache und Stimme sind möglicherweise wertvolle Marker für die Krankheit sein
# Vortrag 2
Die PRISMA Richtlinien in 4 Schritten

# Vortrag 2
Aufnahmekriterien
▶ Keine Sprachbeschränkungen
▶ Veröffentlicht in English zwischen 2013 und 2023
▶In von Experten begutachteten Fachzeitschriften veröffentlicht (peer-reviewed)
▶ Sowohl von Parkinson betroffene Menschen als auch gesunde Menschen sind im Trainingsdatenset enthalten
▶ Mindestens einer ihrer Schwerpunkte liegt auf der Erkennung von Parkinson durch Erkennungsmerkmale aus der Vokalproduktion
▶ Keine Übersichtsartikel
# Vortrag 2
Kodierungsschema und einbezogene Studien
# Vortrag 2
Die Zahlenunterschiede zwischen Parkinsonkranken
und gesunden Teilnehmern
▶ Um die Stichprobengröße zu untersuchen zu können, teilte ich die Anzahl der Parkinson-Gruppe durch die Anzahl der gesunden Gruppe.
▶ Wenn das Ergebnis 1 ist, ist die Stichprobengröße ausgewogen.


# Vortrag 2
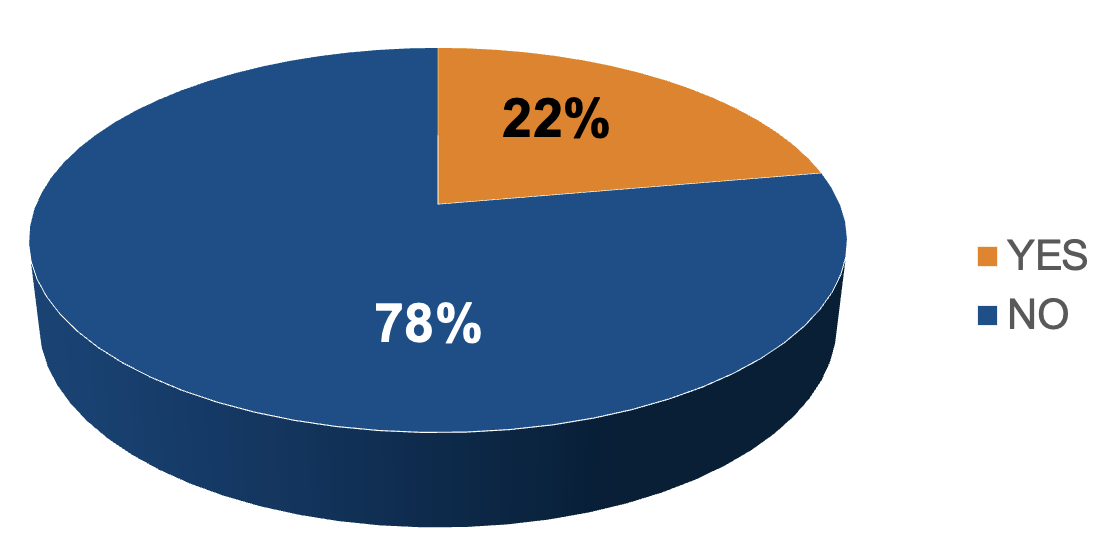
Berücksichtigung des unausgewogenen
Stichprobenumfangs
▶ 2 Studien berücksichtigen eine Wirkung der unausgewogenen Stichprobengröße
▶ 7 Studien berücksichtigen keine Wirkung
# Vortrag 2
Der Einfluss der Stichprobengröße

# Vortrag 2
▶ In Studien zur Früherkennung von Parkinson im Zeitraum 2013-2023
... besteht bei 60% der analysierten Studien ein Ungleichgewicht in der
Stichprobengröße.
... berücksichtigen die meisten Studien mit unausgewogenem
Stichprobenumfang die Wirkung dieser Unausgewogenheit nicht (78 %).
... hat die Unausgewogenheit keinen Einfluss auf die
Klassifizierungsgenauigkeit oder auf signifikante Unterschiede in den
Merkmalen, die aus der Vokalproduktion der beiden Gruppen
hervorgehen.
... geht hevor, dass es trotz unausgewogener Teilnehmerzahl möglich ist,
Patienten mit Anzeichen von Parkinson zu identifizieren.
# Vortrag 2
Fazit
▶ Es gibt eine unausgewogene Stichprobengröße, aber in allen einbezogenen Studien.
▶ Die meisten von ihnen berücksichtigen diese Unausgewogenheit nicht.
▶ Die Unausgewogenheit hat keinen Einfluss auf die Erkennung von Parkinson.
▶ Zukünftige Studien könnten in größerem Umfang bezüglich des Geschlechts oder Alters durchgeführt werden.
# Vortrag 2
EinleitungQUELLEN
Lakens, Daniel (2022). “Sample size justification”. In: Collabra: psychology 8.1, p. 33267.
Liu, Wei et al. (2023). “Prediction of Parkinson’s disease based on artificial neural networks using speech datasets”. In: Journal of Ambient Intelligence and Humanized Computing 14.10, pp. 13571–13584.
Martínez-Nicolas, Israel et al. (2022). ´ “Speech biomarkers of risk factors for vascular dementia in people with mild cognitive impairment”. In: Frontiers in Human Neuroscience 16, p. 1057578.
Ngo, Quoc Cuong et al. (2022). “Computerized analysis of speech and voice for Parkinson’s disease: A systematic review”. In: Computer Methods and Programs in Biomedicine 226, p. 107133.
Rusz, Jan et al. (2013). “Imprecise vowel articulation as a potential early marker of Parkinson’s disease: effect of speaking task”. In: The Journal of the Acoustical Society of America 134.3, pp. 2171–2181.
Uman, Lindsay S (2011). “Systematic reviews and meta-analyses”. In: Journal of the Canadian Academy of Child and Adolescent Psychiatry 20.1, p. 57.
# Navigation
Navigation
# Themenblock anklicken um
# ihn auszuwählenWas ist Phonetik und wozu das Labor? Ein interaktives Erlebnis aus der Ich-Perspektive
Die Scottish Vowel Length RuleInhaltsverzeichnis
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Eine besonders kennzeichnende Eigenschaft des Schottisches Standard Englisch (SSE)
▶ Maßgebende Regel für Vokallänge in SSE.
▶ Die Scottish Vowel Length Rule (SVLR) legt 3 Situationen fest, die einen vorhergehenden Vokal lang werden lassen:
# Vortrag 3
Die Scottish Vowel Length Rule
1. Stimmhafte Frikative: ease [iːz] ist lang, fleece [flis] ist kurz
(Beispielwörter sind kursiv, phonetische Transkriptionen in eckigen Klammern)
# Vortrag 3
▶ Eine besonders kennzeichnende Eigenschaft des Schottisches Standard Englisch (SSE)
▶ Maßgebende Regel für Vokallänge in SSE.
▶ SVLR legt 3 Situationen fest, die einen vorhergehenden Vokal lang werden lassen:
Die Scottish Vowel Length Rule
▶ Eine besonders kennzeichnende Eigenschaft des Schottisches Standard Englisch (SSE)
▶ Maßgebende Regel für Vokallänge in SSE.
▶ SVLR legt 3 Situationen fest, die einen vorhergehenden Vokal lang werden lassen:
1. Stimmhafte Frikative: ease [iːz] ist lang, fleece [flis] ist kurz
2. /r/: bird [biːrd] ist lang, bead [bid] ist kurz
(Beispielwörter sind kursiv, phonetische Transkriptionen in eckigen Klammern)
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Eine besonders kennzeichnende Eigenschaft des Schottisches Standard Englisch (SSE)
▶ Maßgebende Regel für Vokallänge in SSE.
▶ SVLR legt 3 Situationen fest, die einen vorhergehenden Vokal lang werden lassen:
1. Stimmhafte Frikative: ease [iːz] ist lang, fleece [flis] ist kurz
2. /r/: bird [biːrd] ist lang, bead [bid] ist kurz
3. Morphemgrenzen: agree# [əgriː#] und agree#d [əgriː#d] sind lang,
greed# [grid#] ist kur
(Beispielwörter sind kursiv, phonetische Transkriptionen in eckigen Klammern)
# Vortrag 3
Die Scottish Vowel Length Rule
1. Stimmhafte Frikative: ease [iːz] ist lang, fleece [flis] ist kurz
2. /r/: bird [biːrd] ist lang, bead [bid] ist kurz
3. Morphemgrenzen: agree# [əgriː#] und agree#d [əgriː#d] sind lang,
greed# [grid#] ist kur
▶ In allen anderen Situationen diktiert die SVLR einen kurzen Vokal.
▶ Ob sie aber für alle Vokale oder nur für ein Subset gilt, sorgt in der Forschung schon seit Jahrzehnten für Diskussion.
▶ Diese Studie untersucht, ob und für welche Vokale die SVLR wirksam ist.
# Vortrag 3
Die Scottish Vowel Length Rule
Wie misst man die Länge von Sprachlauten?
# Vortrag 3
Die Scottish Vowel Length Rule
Wie misst man die Länge von Sprachlauten?
▶ Gesprochene Wörter (Items) aus Audioaufzeichnungen
(selbst produzierte oder vorhandene aus Datenbanken/Archiven)
# Vortrag 3
Die Scottish Vowel Length Rule
Wie misst man die Länge von Sprachlauten?
▶ Gesprochene Wörter (Items) aus Audioaufzeichnungen
(selbst produzierte oder vorhandene aus Datenbanken/Archiven)
▶ Daten dieser Studie: SSE-Aufzeichnungen aus IDEA
# Vortrag 3
Die Scottish Vowel Length Rule
Wie misst man die Länge von Sprachlauten?
▶ Gesprochene Wörter (Items) aus Audioaufzeichnungen
(selbst produzierte oder vorhandene aus Datenbanken/Archiven)
▶ Daten dieser Studie: SSE-Aufzeichnungen aus IDEA

▶ Internetarchiv mit ungefähr 1.700 Aufnahmen aus über 135 Ländern/Territorien von verschiedenen Dialekten des Englischen, davon 27 SSE-Aufzeichnungen
# Vortrag 3
Die Scottish Vowel Length Rule
Wichtig: Kontrolle der Daten auf mögliche Faktoren, die die Ergebnisse beeinflussen könnten
▶ Ausschluss aller Sprecher, die den Zieltext nicht produziert haben
▶ Ausschluss aller Sprecher mit starken SVLR-externen Sprachkontakt
# Vortrag 3
Die Scottish Vowel Length Rule
Wichtig: Kontrolle der Daten auf mögliche Faktoren, die die Ergebnisse beeinflussen könnten
▶ Gleicher Anteil weiblicher und männlicher Sprecher
▶ Items müssen Zielvokal enthalten
▶ Items müssen möglichst in einer betonten Position sein
# Vortrag 3
Die Scottish Vowel Length Rule
Wichtig: Kontrolle der Daten auf mögliche Faktoren, die die Ergebnisse beeinflussen könnten
▶ Items müssen Akzent auf Vokal haben
▶ Ausschluss „fehlerhafter“ Itemproduktionen
# Vortrag 3
Die Scottish Vowel Length Rule
Wichtig: Kontrolle der Daten auf mögliche Faktoren, die die Ergebnisse beeinflussen könnten
▶ Für jeden Vokal wurden 6 Items ausgewählt, je 3 in Umgebungen, in denen die SVLR kurze oder lange Vokale diktiert.
▶ Das Datenset umfasste am Ende 8 Sprecher (S1-S8) und 36 Items pro Sprecher. 8 Äußerungen wurden aufgrund von qualitativ unzufriedenstellender Produktion ausgeschlossen, für insgesamt 280 Datenpunkte.
# Vortrag 3
Die Scottish Vowel Length Rule



Um die genaue Länge der Vokale zu messen, müssen sie zuerst von den anderen Sprachlauten segmentiert werden. Dafür werden die sogenannten Formanten verwendet. Anhand ihrer kann man die Vokale im Vokalsystem identifizieren und voneinander differenzieren:
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Menschliche Sprache besteht aus komplexen Schallwellen (d.h. Signale, die aus mehreren einzelnen Schallwellen bestehen)
▶ Diese individuellen Schallwellen haben unterschiedliche Frequenzen (Wiederholungsraten)
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Ein zeitlicher Querschnitt einer komplexen Schallwelle, in dem die Frequenzen der beinhalteten Schallwellen und ihre Lautstärke dargestellt werden, heißt Spektrum
▶ Die lautesten dieser Frequenzen sind die Formanten (F0, F1, F2...)
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Ein zeitlicher Verlauf eines Spektrums heißt Spektrogramm
▶ Formanten sind im Spektrogramm an der Dunkelheit zu erkennen
▶ Diese Formantenstruktur ist für jeden Vokal einzigartig, quasi eine Art Fingerabdruck
# Vortrag 3
Die Scottish Vowel Length Rule
Praat ist eine freie Software für phonetische Analysen auf Signalbasis, entwickelt von Paul Boersma und David Weenink (https://www.fon.hum.uva.nl/praat/). Die einzelnen Items und
Vokale in den Audioaufzeichnungen wurden in Praat mit einem TextGrid annotiert:

# Vortrag 3
Die Scottish Vowel Length Rule
Praat ist eine freie Software für phonetische Analysen auf Signalbasis, entwickelt von Paul Boersma und David Weenink (https://www.fon.hum.uva.nl/praat/). Die einzelnen Items und Vokale in den Audioaufzeichnungen wurden in Praat mit einem TextGrid annotiert:
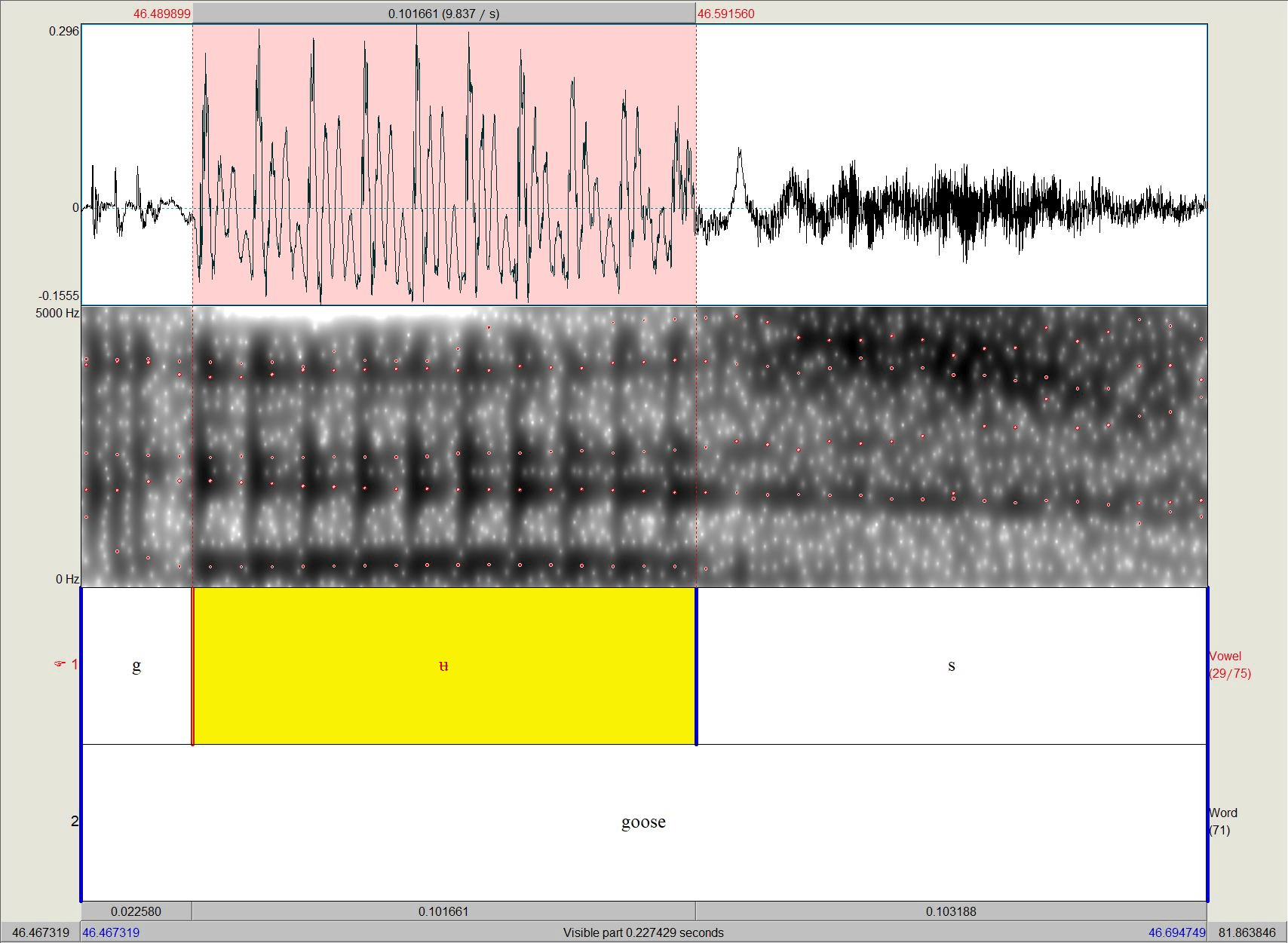
▶ Bild: Länge /ʉ/ in goose = 0,102s
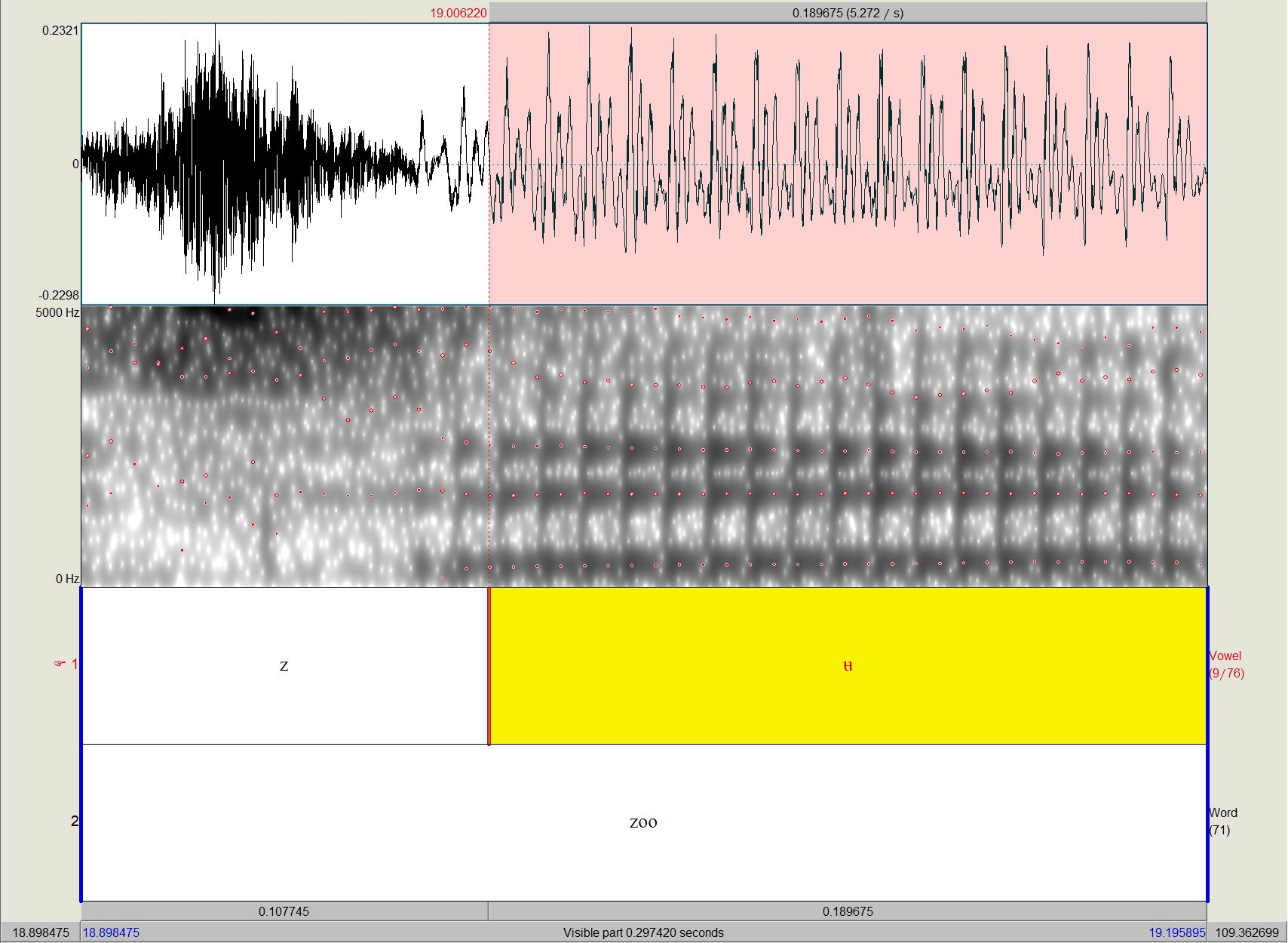
▶ Bild: Länge /ʉ/ in you = 0,189s
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Bild: Länge /ʉ/ in goose = 0,102s
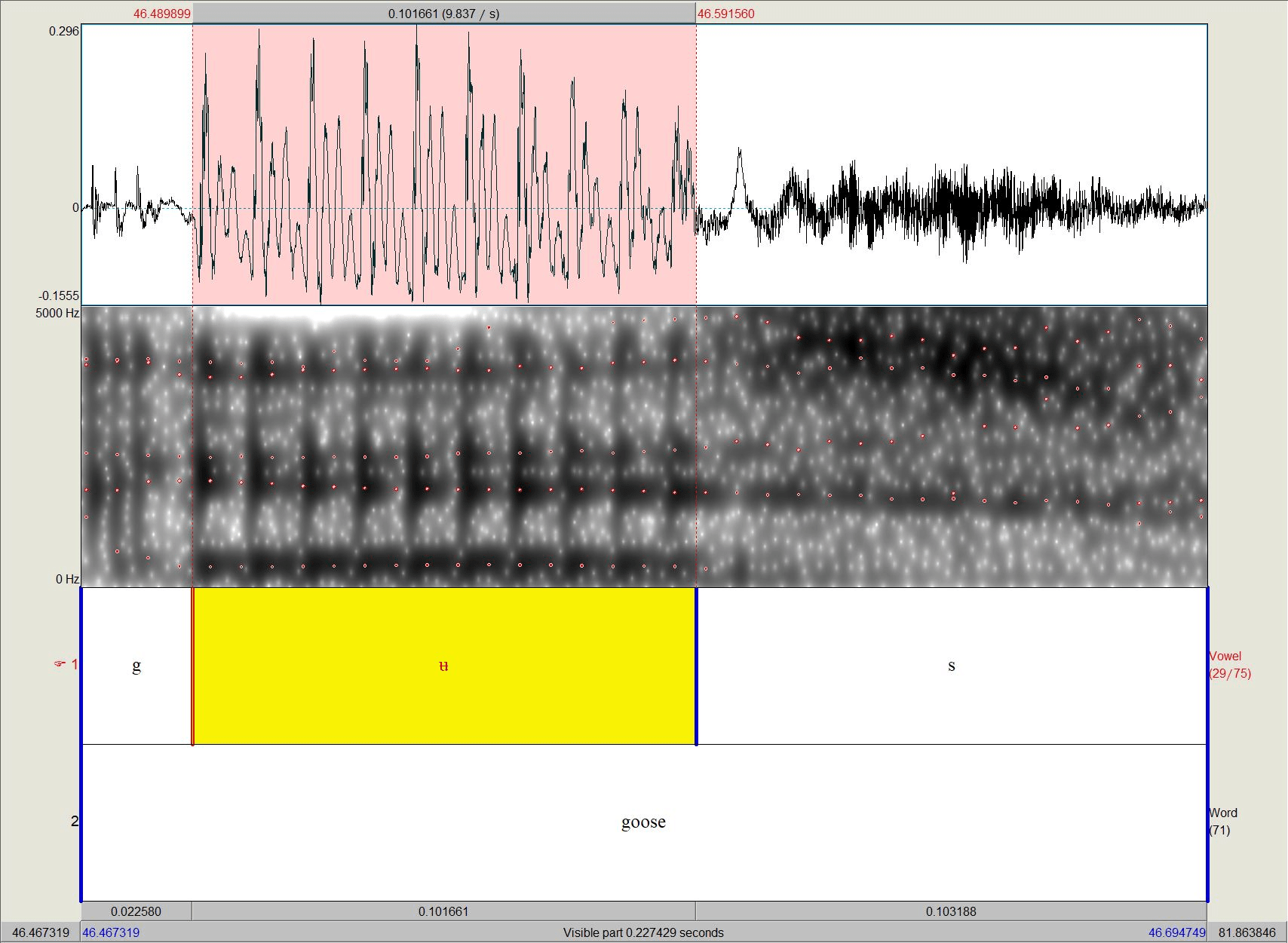
▶ Reihe 1: Lautstärke (Amplitude)
▶ Reihe 2: Spektrogramm (Formanten von Praat mir rot gestrichelter Linie gekennzeichnet)
▶ Reihe 3: Annotierung Sprachlaut
▶ Reihe 4: Annotierung Item
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Längen der einzelnen Segmente lassen sich von Praat ausgeben.
▶ Manuelle Segmentierung, Annotation
und Datenauslesung ist zeitaufwendig
# Vortrag 3
Die Scottish Vowel Length Rule
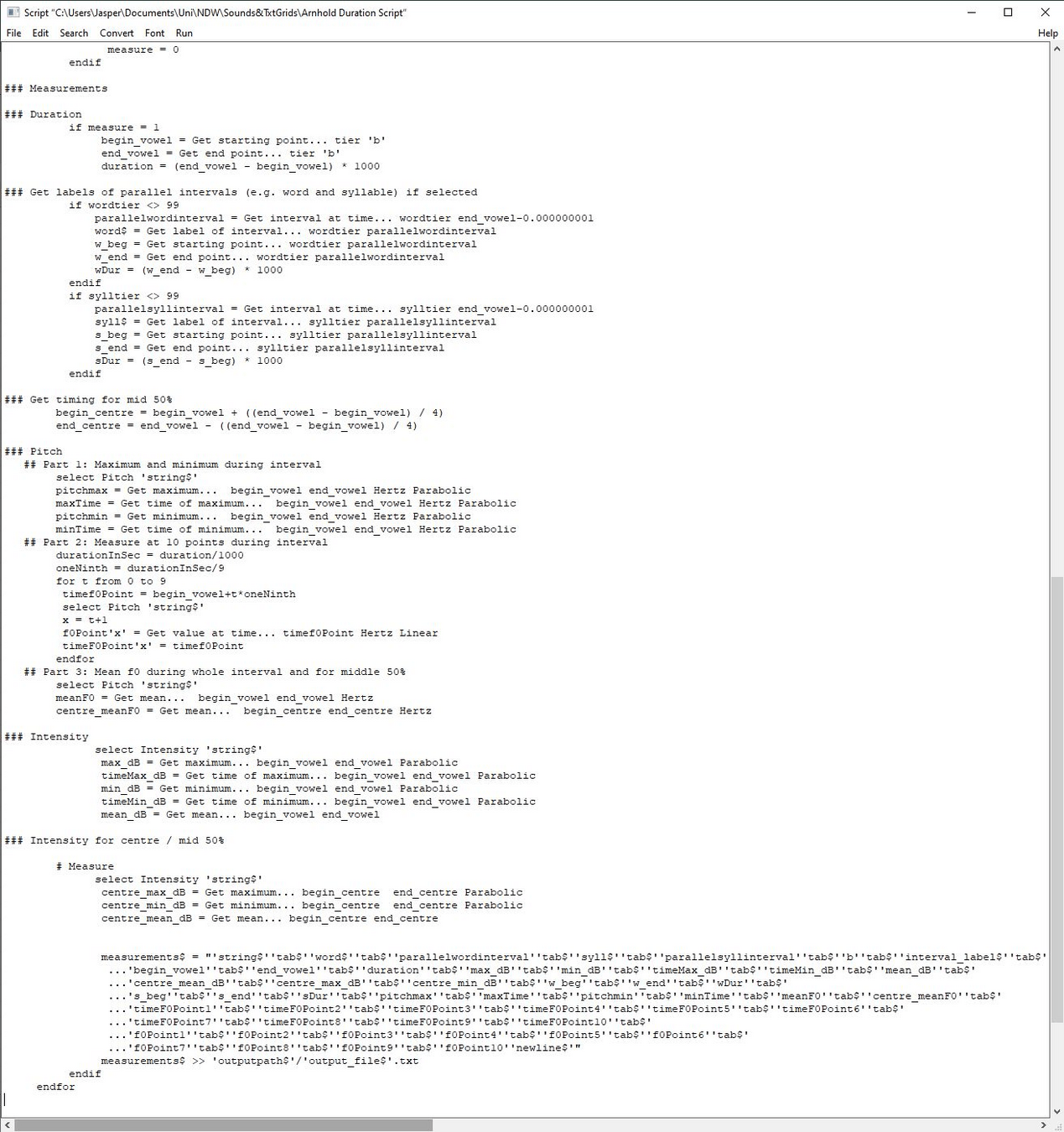
▶ Praat Scripts
Teil eines Prosody Measurement Scripts, das in annotierten Audioaufzeichnungen mehrere prosodische Werte messen kann, darunter auch die Länge einzelner Segmente

(geschrieben von Katherine Crosswhite und modifiziert von Taehong Cho, Holger Mitterer & Anja Arnhold; https://sites.ualberta.ca/~arnhold/scripts/OnlyMeasurements/MeasureIntensityDurationF0minF0maxF0contourpoints.praat)
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Diese Längenmessungen für SVLR-kurze und SVLR-lange Umgebungen lassen sich dann für die einzelnen Sprecher vergleichen.
▶ Da individueller Sprachgebrauch einen Vergleich absoluter Differenzen unmöglich macht, werden diese in prozentualer Veränderung von kurzen zu langen Umgebungen angegeben.
# Vortrag 3
Die Scottish Vowel Length Rule
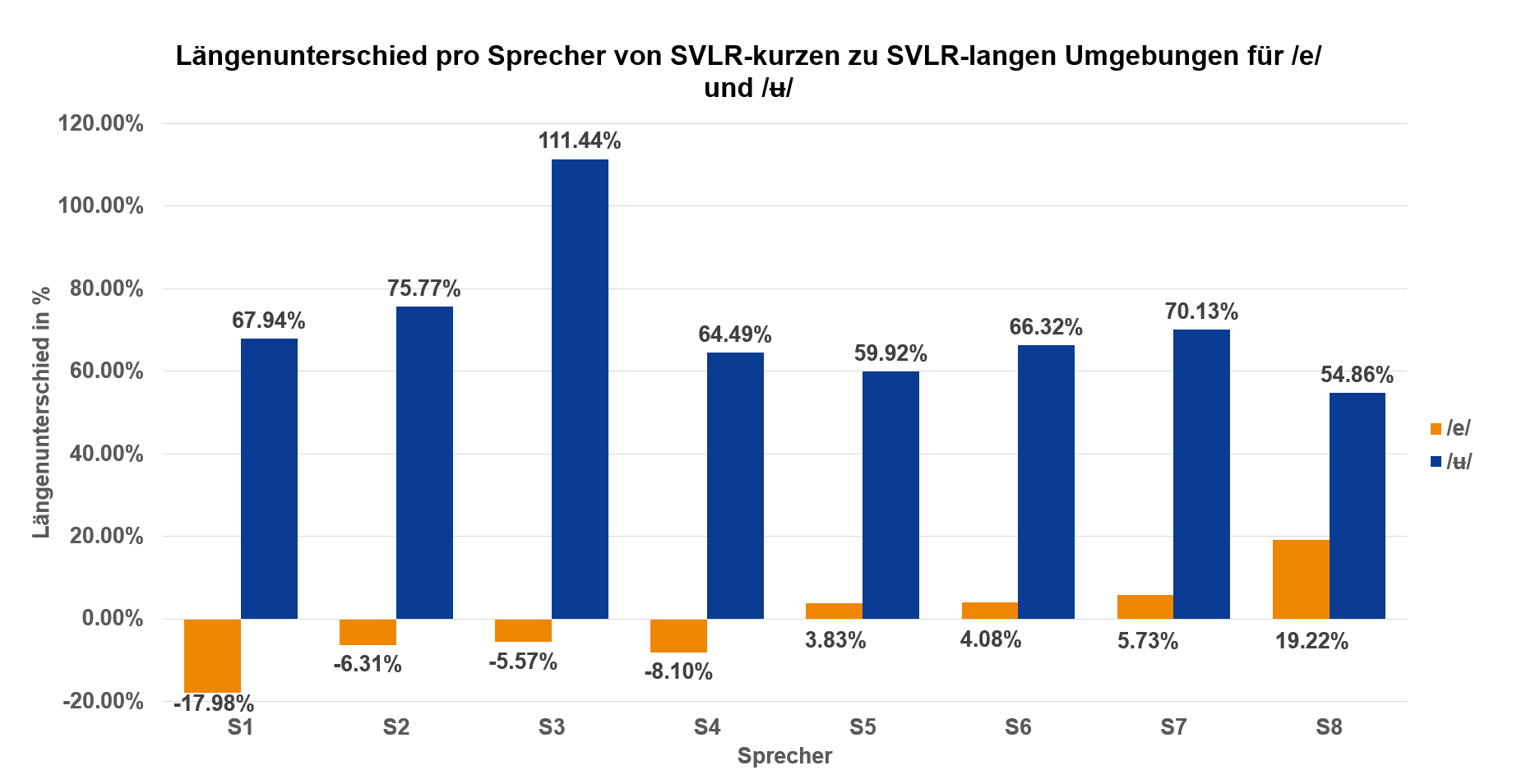
# Vortrag 3
Die Scottish Vowel Length Rule
▶ Vokale mit eindeutigem SVLR-Effekt:
• /i/: 92%
• /ʉ/: 71%
• /aɪ/: 15%
▶ Vokale ohne eindeutigen SVLR-Effekt:
• /o/: -21%
• /e/: -1%
• /ɔ/: -23%
▶ Im Bezug auf die Forschungsfrage zum Wirkungsbereich der SVLR ergibt sich daraus folgender Befund:
Die SVLR gilt nicht für alle Vokale in SSE, sondern nur für das Subset der Vokale /i ʉ aɪ/.
# Vortrag 3
Navigation
# Themenblock anklicken um
# ihn auszuwählen# Navigation
Anglistik Voices
▶ Begrenzte L2-Englisch-Sprachkorpora mit Akzent
▷ Nennenswerte Ausnahmen sind der Wildcat [1] und der ArtieBias [2] Korpus, wobei diese auch einige Probleme aufweisen:
# Vortrag 4
Anglistik Voices
▶ Begrenzte L2-Englisch-Sprachkorpora mit Akzent
▷ Nennenswerte Ausnahmen sind der Wildcat [1] und der ArtieBias [2] Korpus, wobei diese auch einige Probleme aufweisen:
1. Fehlende detaillierte linguistische Profile
2. Überwiegend durch Crowdsourcing erstellt, was die Qualität beeinträchtigt
3. Wenige hochmoderne Speech-to-Text-Modelle wurden auf L2-Englisch
getestet [3]
# Vortrag 4
Anglistik Voices
▶ Bildungslücke im Bereich KI und Technologie
▷ Hervorgehoben durch: EU-Vorschriften wie den AI ACT [4]
▷ Bedeutung: Transparenz und Bildung in der KI
▷ Auswirkungen: Einbeziehung von Akzenten und Minderheitengruppen
1. Fehlende detaillierte linguistische Profile
2. Überwiegend durch Crowdsourcing erstellt, was die Qualität beeinträchtigt
3. Wenige hochmoderne Speech-to-Text-Modelle wurden auf L2-Englisch
getestet [3]
# Vortrag 4
Anglistik Voices
▶ Erstellung eines Korpus in einem Seminar, um beide Probleme gleichzeitig anzugehen
▷ Entworfen nach dem CARE-Ansatz (Collaborative, Active, Research-focused, Educational) [5]
▷ Fokussiert auf den Aufbau eines Englisch-L2 Sprachdatensatzes und die Evaluierung aktueller Spracherkennungssysteme
▷ Studierende sammeln Erfahrungen in der Durchführung von Experimenten im Bereich Phonetik/Phonologie und erlangen ein grundlegendes Verständnis der automatischen Spracherkennung (ASR)
# Vortrag 4
Anglistik Voices
▶ Kursrahmen
▷ 2. Studienjahr, Bachelorseminar im Fachbereich Anglistik
▷ Einmal pro Woche über ein Semester (14 Wochen)
▷ Nutzung von sowohl Labor- als auch Unterrichtsumgebungen
▷ Keine technischen Vorkenntnisse vorausgesetzt
# Vortrag 4
Anglistik Voices
▶ Schritt 1: Erstellung des Korpus
▷ Gruppen von drei Studierenden
▷ Jede*r Studierende übernimmt jede Rolle einmal
▷ Die Teilnehmenden nehmen Stimuli aus dem ArtieBias-Korpus auf
▷ Das Experiment wurde im Phonetiklabor mit Audacity durchgeführt [6]
▷ Manuelle Satz-für-Satz-Alignierung
Satz 1 – Audio File 1
Satz 2 – Audio 2
...
# Vortrag 4
Anglistik Voices
▶ Schritt 2: Evaluation
▷ Studierende transkribierten Audioaufnahmen mit ASR-Modellen, die auf Huggingface gehostet sind
▷ Die Transkriptionen der Modelle wurden manuell anhand der Wortfehlerrate (Word Error Rate) evaluiert und auf mögliche Fehlerquellen analysiert
# Vortrag 4
Anglistik Voices
▶ Schritt 2: Evaluation
▷ Studierende transkribierten Audioaufnahmen mit ASR-Modellen, die auf Huggingface gehostet sind
▷ Die Transkriptionen der Modelle wurden manuell anhand der Wortfehlerrate (Word Error Rate) evaluiert und auf mögliche Fehlerquellen analysiert

▷ Die Ergebnisse der Studierenden bestätigen die Erkenntnisse aus [3], dass
moderne ASR-Modelle Schwierigkeiten
mit unterschiedlichen Sprechweisen
haben
# Vortrag 4
Anglistik Voices
▶ 20 Sprecher*innen, 1200 Stimuli (Sätze), 60 Sätze pro Teilnehmer*in
▶ Etwa 150 Minuten gelesene L2-Englisch-Sprache
▶ Lizenz: CC-BY-4-SA
▶ Gesammelte Metadaten:
# Vortrag 4
Anglistik Voices
▶ 20 Sprecher*innen, 1200 Stimuli (Sätze), 60 Sätze pro Teilnehmer*in
▶ Etwa 150 Minuten gelesene L2-Englisch-Sprache
▶ Lizenz: CC-BY-4-SA
▶ Gesammelte Metadaten:
-> Alter: 19-30
-> Geschlecht: 14 weiblich, 6 möchten keine Angabe machen
-> Höchster Bildungsabschluss: Abitur, Bachelor, Diplom
-> Erstsprache(n): Albanisch, Deutsch, Vietnamesisch, Lingala, Französisch, Rumänisch, Griechisch, Russisch, Kannada
# Vortrag 4
Anglistik Voices
▶ 20 Sprecher*innen, 1200 Stimuli (Sätze), 60 Sätze pro Teilnehmer*in
▶ Etwa 150 Minuten gelesene L2-Englisch-Sprache
▶ Lizenz: CC-BY-4-SA
▶ Gesammelte Metadaten:
-> Alter: 19-30
-> Geschlecht: 14 weiblich, 6 möchten keine Angabe machen
-> Höchster Bildungsabschluss: Abitur, Bachelor, Diplom
-> Erstsprache(n): Albanisch, Deutsch, Vietnamesisch, Lingala, Französisch, Rumänisch, Griechisch, Russisch, Kannada
-> Weitere Sprachen: Englisch, Spanisch, Französisch, Japanisch, Deutsch,
Mandarin, Italienisch, Hindi
-> Erwerbsalter jeder Sprache: 2-21 Jahre
-> Weitere Daten: Hauptquelle des Englischunterrichts, sekundäre/weitere
Quellen, Ergebnisse offizieller Englischtests (TOEFL, OOPT, ...), Zeit in einem englischsprachigen Land verbracht, Land, in dem sie aufgewachsen sind
# Vortrag 4
# Vortrag 4
Anglistik Voices
▶ Analyse der ASR Modelle
-> Die Wortfehlerrate (WER) ist das Verhältnis der falsch erkannten Wörter zur Gesamtzahl der gesprochenen Wörter
Anglistik Voices
▶ Analyse der ASR Modelle
-> Die Wortfehlerrate (WER) ist das Verhältnis der falsch erkannten Wörter zur Gesamtzahl der gesprochenen Wörter
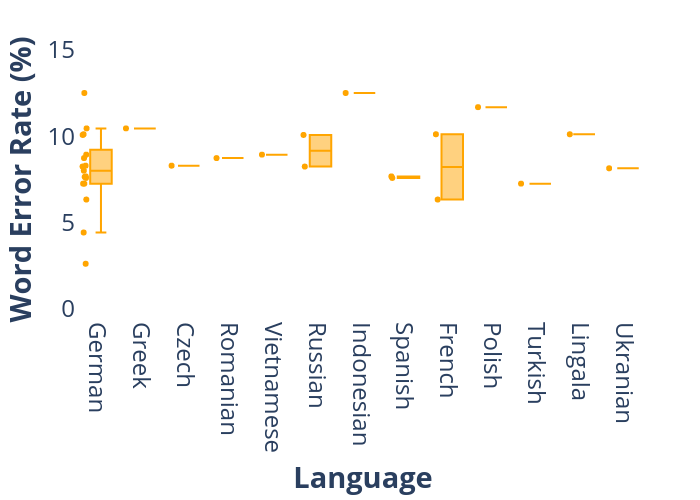
▶ Whisper
-> Version: medium.en
-> Trainiert auf 680.000 Stunden
mehrsprachiger Sprache, feinabgestimmt auf Englisch
-> Die WER (%) für standardisiertes, Amerikanisches
Englisch beträgt 6,08 %
# Vortrag 4
Anglistik Voices
# Vortrag 4
Anglistik Voices
▶ Machbarkeitsnachweis zur gleichzeitigen Bewältigung von Bildungs- und technologischen Herausforderungen in der Sprachtechnologie
▶ Studierende verfassten eine Seminararbeit, um Forschungsergebnisse zu berichten und zu reflektieren
▶ Unser Lehransatz fördert das Verständnis für technologische Fortschritte und die Grenzen der KI
# Vortrag 4
Anglistik Voices
▶ Machbarkeitsnachweis zur gleichzeitigen Bewältigung von Bildungs- und technologischen Herausforderungen in der Sprachtechnologie
▶ Studierende verfassten eine Seminararbeit, um Forschungsergebnisse zu berichten und zu reflektieren
▶ Unser Lehransatz fördert das Verständnis für technologische Fortschritte und die Grenzen der KI
▶ Aktuelle ASR-Modelle haben Schwierigkeiten mit Akzentvariationen in der Sprache
▶ Whisper schneidet besser ab als Deepspeech bei verschiedenen englischen Akzenten
▶ Die Lizenz ermöglicht es, den Korpus in zukünftigen Durchläufen dieses Kursformats zu erweitern
# Vortrag 4
Quellen[1] A . R. Bradlow, R. E. Baker, A. Choi, M. Kim, and K. J. Van Engen, “The Wildcat Corpus
of Native-and Foreign-accented English,” Journal of the Acoustical Society of America, vol.
121, no. 5, p. 3072, 2007.
[2] J. Meyer, L. Rauchenstein, J. D. Eisenberg, and N. Howell, “Artie bias corpus: An open
dataset for detecting demographic bias in speech applications,” in proceedings of the
twelfth language resources and evaluation conference, 2020, pp. 6462–6468.
[3] C. Graham and N. Roll, “Evaluating openai’s whisper asr: Performance analysis across
diverse accents and speaker traits,” JASA Express Letters, vol. 4, no. 2, 2024.
[4] “The Act texts | EU Artificial Intelligence Act.” https://artificialintelligenceact.eu/the-act/
[5] C. Bjorndahl and M. Gibson, “The care approach to incorporating undergraduate
research in the phonetics/phonology classroom,” Language, vol. 98, no. 1, pp. e1–e25,
2022.
[6] Audacity Team. Audacity. Version 3.2.4, 2024. https://www.audacityteam.org/
# Vortrag 4
Navigation
# Themenblock anklicken um
# ihn auszuwählen# Navigation
# Vortrag 5
Inhaltsverzeichnis
▶ Beeinflusst die Parteizugehörigkeit der nordenglischen Abgeordneten ihre Akzentvariation, und wenn ja, wie beeinflusst sie ihre Akzentvariation?
▶ Beeinflusst der Bildungshintergrund der nordenglischen Abgeordneten ihre Akzentvariation, und wenn ja, wie beeinflusst er ihre Akzentvariation?
# Vortrag 5
▶ Alter
Generationsunterschiede könnten Marker des Nordenglischen beeinflussen.
▶ Parteizugehörigkeit
Die Zugehörigkeit zur Received Pronunciation könnte durch die Parteizugehörigkeit beeinflusst werden.
▶ Bildungshintergrund
Die Zugehörigkeit zur Received Pronunciation könnte durch den Bildungshintergrund beeinflusst werden.
In der Linguistik ist Received Pronunciation (RP)
eine prestigeträchtige, standardisierte Form des britischen Englisch, die historisch mit Bildung und der oberen Gesellschaftsschicht verbunden ist. RP wird oft als "Queen's English" bezeichnet und hat keine spezifische regionale Zuordnung.
# Vortrag 5
▶ STRUT-FOOT sind unterschiedliche Vokale: /ʌ/; /ʊ/
▶ TRAP-BATH sind unterschiedliche Vokale : /æ/; /a:/
▶ GOOSE wird nach vorne verlagert: /uː/ → /ʉ/,/y/
▶ FACE wird diphthongiert: /eɪ/
▶ GOAT wird diphthongiert: /əʊ/
▶ HappY wird gedehnt ausgesprochen: /i:/
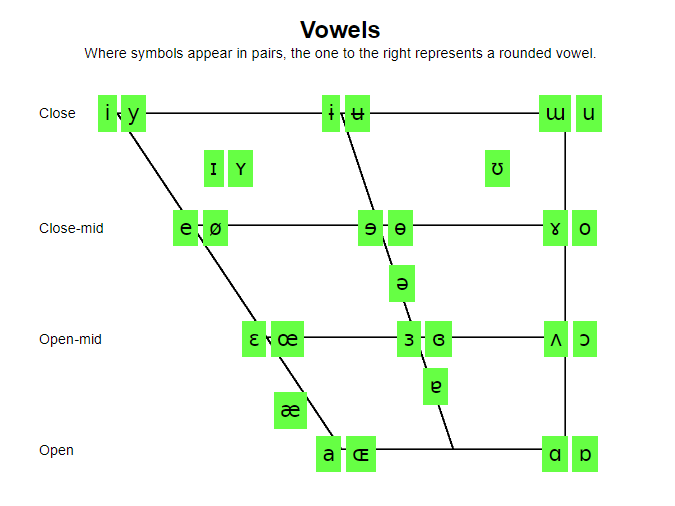
# Vortrag 5
▶ STRUT-FOOT sind verschmolzen: /ʌ/ → /ʊ/
▶ FACE wird monophongisiert: /eɪ/ → /e:/
▶ GOAT wird monophongisiert : /əʊ/ → /o:/
▶ Gelockerte ausgesprochenes HappY: /ɪ/
# Vortrag 5
▶ Konservative Sprecher zeigen mehr Akzentmerkmale, die auf RP- Akzente hinweisen. Sprecher aus der Arbeiterklasse zeigen mehr Akzentmerkmale, die auf nordenglische Akzente hinweisen.
▶ Privat unterrichtete Sprecher zeigen mehr Akzentmerkmale, die auf RP- Akzente hinweisen. Staatlich unterrichtete Sprecher zeigen mehr Akzentmerkmale, die auf nordenglische Akzente hinweisen.
# Vortrag 5
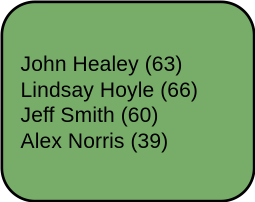
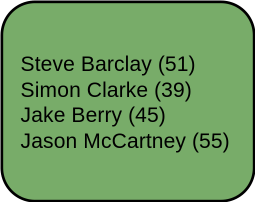
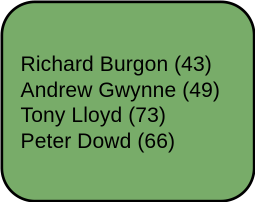
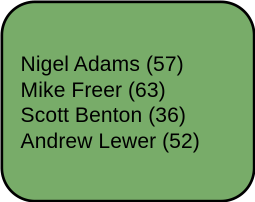
▶ Arbeiterpartei und privat unterrichtet
▶ konservativ und privat unterrichtet
▶ Arbeiterpartei und staatlich unterrichtet
▶ konservativ und staatlich unterrichtet
# Vortrag 5
▶ Nur Parlamentsreden der letzten fünf Jahre
▶ Abgerufen über YouTube und Parliamentlive.tv
▶ Heruntergeladen und in .mp3 konvertiert
# Vortrag 5
▶ Die .mp3-Dateien wurden in Praat geladen
▶ Die Formantenfrequenzen F1 und F2 wurden gemessen mithilfe des Computerprogramms Praat

# Vortrag 5
▶ Die Formantenmessungen wurden anschließend mithilfe der Methode von Watts und Fabrizius normalisiert und in R für die Lesbarkeit formatiert.
Die Watts und Fabrizius Methode normalisiert Formantenmessungen, indem sie sie an Referenzwerte anpasst. Dies geschieht durch Berechnung von Mittelwerten und Standardabweichungen, um Unterschiede durch Sprecher oder Aufnahmebedingungen zu korrigieren und die Daten vergleichbar zu machen.
# Vortrag 5
▶ Statistische Unterschiede wurden auf Signifikanz getestet, indem eine Bottom-up-Mixed-Effects-Regression verwendet wurde.
Mixed Effects Regression: Dies ist eine statistische Methode, die sowohl feste Effekte (systematische Einflüsse) als auch zufällige Effekte (variierende Einflüsse zwischen Gruppen oder Individuen) berücksichtigt. Sie ist besonders nützlich, wenn Daten hierarchisch strukturiert sind oder wenn es Unterschiede zwischen den Gruppen gibt, die in den Modellannahmen berücksichtigt werden müssen.
# Vortrag 5
▶ Statistische Unterschiede wurden auf Signifikanz getestet, indem eine Bottom-up-Mixed-Effects-Regression verwendet wurde.
Bottom-up Ansatz: Dieser Ansatz bedeutet, dass das Modell schrittweise aufgebaut wird, beginnend mit den einfachsten Annahmen und dann komplexere Effekte hinzugefügt werden. Zuerst werden die grundlegenden festen Effekte betrachtet, und dann werden zufällige Effekte und Interaktionen hinzugefügt, um die beste Modellanpassung zu finden.
# Vortrag 5
▶ Statistische Unterschiede wurden auf Signifikanz getestet, indem eine Bottom-up-Mixed- Effects-Regression verwendet wurde.
Signifikanz in der Statistik bezeichnet, ob ein Ergebnis wahrscheinlich durch einen echten Effekt und nicht nur durch Zufall entstanden ist. Ein Ergebnis gilt als signifikant, wenn die Wahrscheinlichkeit, dass es zufällig auftritt, sehr gering ist (typischerweise weniger als 5 %). Signifikanztests helfen dabei, zu entscheiden, ob beobachtete Unterschiede oder Beziehungen in den Daten statistisch bedeutsam sind.
# Vortrag 5

Praat ist ein Computerprogramm, das in der Linguistik verwendet wird, um Sprachaufnahmen zu analysieren und zu bearbeiten. Es ermöglicht die Untersuchung von Sprachlauten auf verschiedenen Ebenen, wie zum Beispiel Akustik, Intonation und Phonetik, und bietet Werkzeuge für die visuelle Darstellung und Analyse von Sprachdaten.
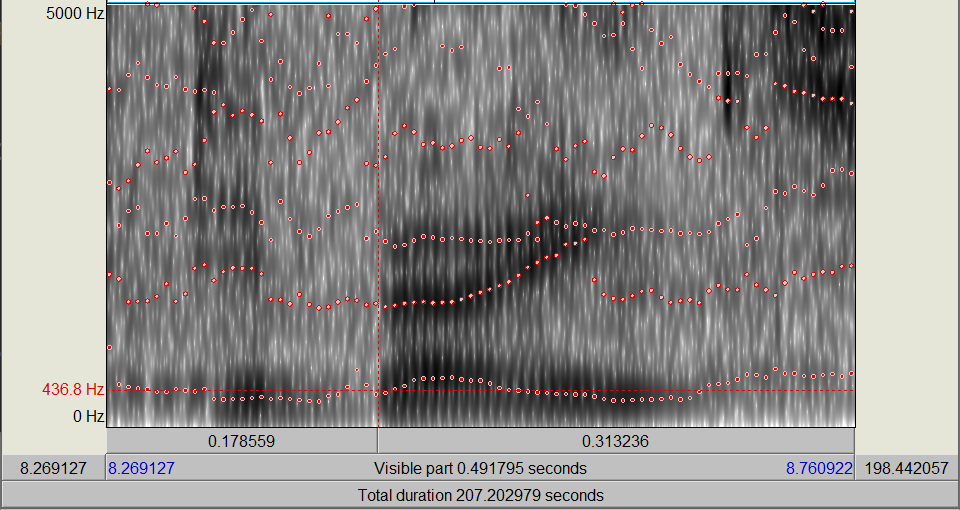
# Vortrag 5
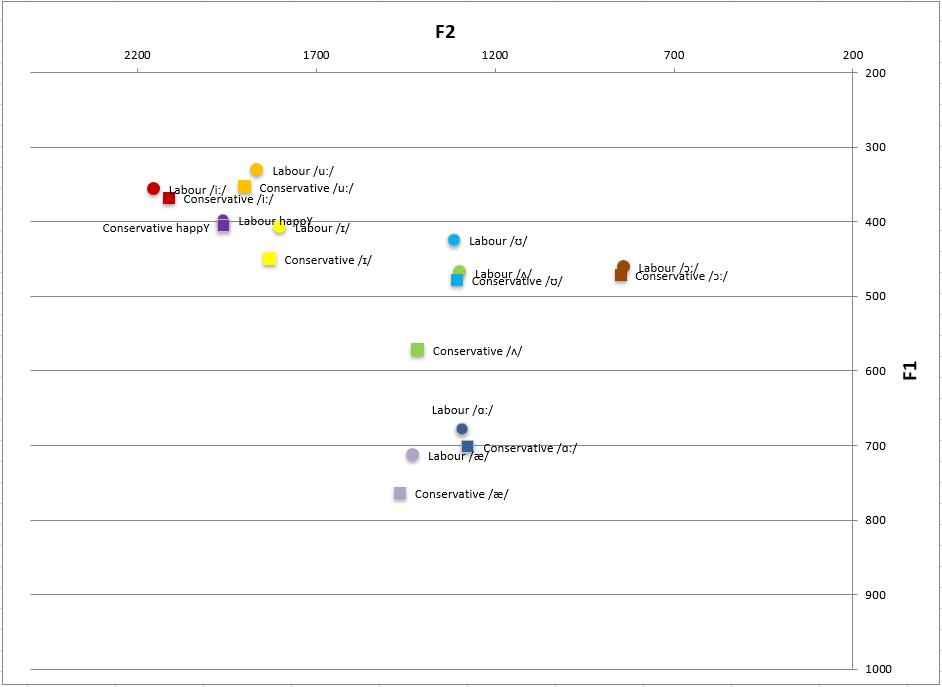
▶ Signifikant tiefere tief-mittlere Vokale bei Konservativen
Konservative Sprecher neigen dazu, tiefere tief-mittlere Vokale zu produzieren im Vergleich zu anderen Gruppen. Diese Vokale (wie in Wörtern wie „Bett“ oder „Strut“) werden mit der Zunge weiter unten im Mund artikuliert.
▶ STRUT-Vokal bei Konservativen signifikant tiefer im Vergleich zu Labour
Der Vokal im Wort „strut“ (in der Phonetik als STRUT-Vokal bekannt) ist bei konservativen Sprechern signifikant tiefer im Vergleich zu Labour-Sprechern.
# Vortrag 5
▶ Kein signifikanter Unterschied zwischen STRUT/FOOT-Vokalen bei Konservativen
Es gibt keinen bedeutsamen Unterschied zwischen der Aussprache der STRUT- und FOOT-Vokale bei konservativen Sprechern. (Der FOOT-Vokal tritt in Wörtern wie „put“ auf.)
▶ Keine systematische Monophthongisierung der FACE-Diphthonge bei Arbeiterparteien
Labour-Sprecher vereinfachen den Diphthong in Wörtern wie „face“ nicht konsequent zu einem Monophthong (einem reinen Vokallaut).
# Vortrag 5
▶ Keine systematische Monophthongisierung der GOAT-Diphthonge bei Politikern der Arbeiterpartei
Ebenso monophthongisieren Politiker der Arbeiterpartei den GOAT-Vokal nicht konsequent.
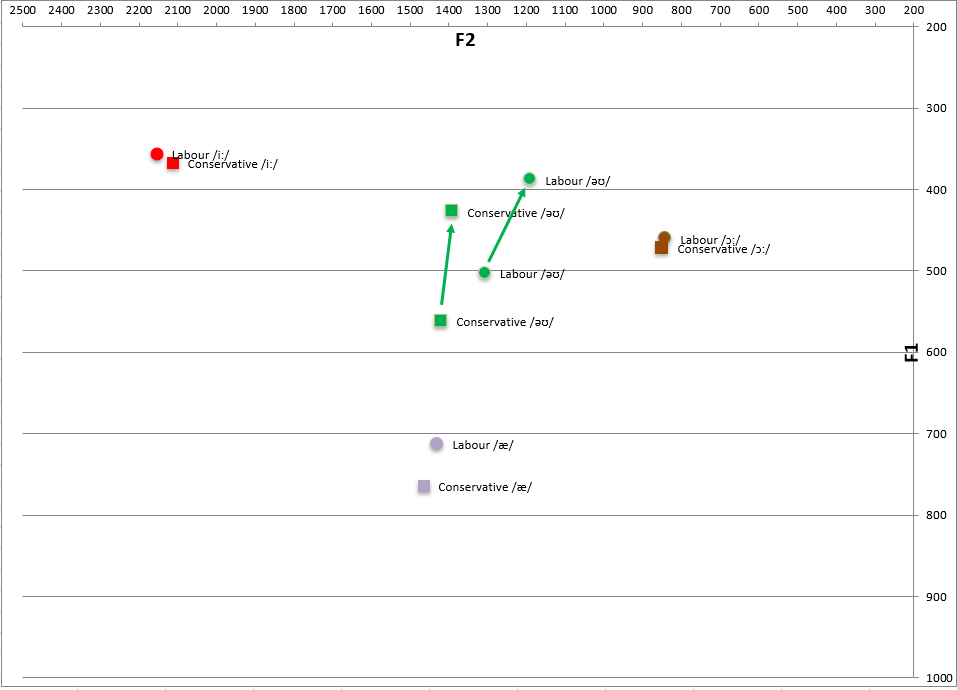
▶ GOOSE-Vorverlagerung verbreitet bei beiden Parteien, aber stärker bei jungen Sprechern
Der GOOSE-Vokal wird bei Sprechern beider Parteien nach vorne verlagert (mit der Zunge weiter vorne im Mund ausgesprochen), aber dieses Merkmal ist bei jüngeren Sprechern stärker ausgeprägt.
# Vortrag 5
# Vortrag 5
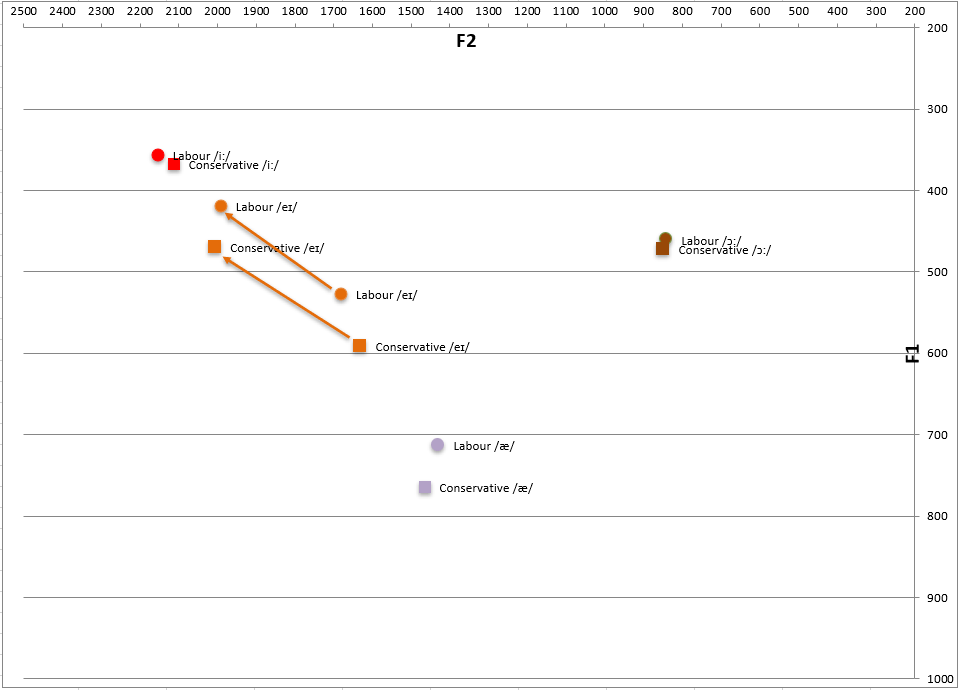
▶ Bezüglich der Diphthongisierung von FACE- und GOAT-Vokalen
Mit wenigen Ausnahmen diphthongisieren sowohl Labour- als auch konservative Sprecher.
▶ Kein signifikanter Unterschied in Bezug auf Δ oder den Euklidischen Abstand.
▶ Unerwarteter Befund
Labour-Sprecher zeigen sowohl angespanntere Anfänge (Onsets) als auch angespanntere Endungen (Offsets).
# Vortrag 5
# Vortrag 5
# Vortrag 5
▶ Die auffälligsten Merkmale nordenglischer Akzente (z. B. STRUT-FOOT- und TRAP-BATH-Verschmelzung) scheinen robuste Indikatoren für den allgemeinen nordenglischen Akzent zu sein.
▶ Weniger auffällige regionale Akzentmerkmale, wie ein lax ausgesprochenes happY und monophthongale FACE/GOAT-Vokale, werden durch Realisierungen ersetzt, die typisch für das Received Pronunciation (RP) sind.
▶ Die Vorverlagerung des GOOSE-Vokals und die weit verbreitete Diphthongisierung scheinen die Ergebnisse der einschlägigen Literatur zu bestätigen.
# Vortrag 5
▶ Nur die Vokalqualität zu Beginn (Onset) und Ende (Offset) der FACE- und GOAT-Vokale scheint politische Bedeutung zu vermitteln und die Parteizugehörigkeit anzuzeigen.
▶ Angespanntere Realisierungen könnten mit ländlichen und altmodischen nordenglischen Akzenten in Verbindung stehen.
# Vortrag 5
Haddican, B., Foulkes, P., Hughes, V., and Richards, H. (2013). Interaction of social and linguistic constraints on two vowel changes in northern england. Language Variation and Change, 25(3):371–403.
Hall-Lew, L., Coppock, E., and Starr, R. L. (2010). Indexing political persuasion: Variation in the iraq vowels. American Speech, 85(1):91–102.
Hall-Lew, L., Friskney, R., and Scobbie, J. M. (2017). Accommodation or political identity: Scottish members of the uk parliament. Language Variation and Change, 29(3):341–363.
Hughes, A., Watt, D., and Trudgill, P. (2013). English accents & dialects. Routledge, Abingdon, Oxon, 5. ed. Edition.
Lindsey, G. (2019). English After RP: Standard British Pronunciation Today. Springer International Publishing, Cham.
Strycharczuk, P., Brown, G., Leemann, A., and Britain, D. (2019). Investigating the foot-strut distinction in northern Englishes using crowdsourced data. Proceedings of the 19th International Congress of Phonetic Sciences, pages 1337–1341.
# Vortrag 5
Navigation
# Themenblock anklicken um
# ihn auszuwählen# Navigation
# Ang3 @HHU
Das Institut für Anglistik und Amerikanistik umfasst sieben Professuren im Bereich der Linguistik, der mittelalterlichen Literatur und den Literaturen der Neuzeit, welche sich aus den Abteilungen der Modern English Literature, American Studies, Anglophone Literatures und Comparative Literature zusammensetzt. Mit etwa 2000 Studierenden und über 50 Mitarbeitenden stellt das Institut für Anglistik und Amerikanistik eines der größten geisteswissenschaftlichen Fächer der Heinrich-Heine-Universität Düsseldorf dar.
# SLaM @HHU
Speech, Language, and Modeling Lab
Gegründet wurde das SLaM Lab von noch damals Dr. Tang und seinen KollegInnen Dr. Wayland und Dr. Wilshire an der University of Florida. Seit Herbst 2020 operiert das Labor mit einer Besatzung von 12 Personen auch in Deutschland an der Heinrich-Heine Universität Düsseldorf.Mit besonderem Schwerpunkt auf der Computerlinguistik, Phonetik und Phonologie erforscht das Team verschiedene sprachliche Phänomene mit quantitativen Methoden und leistet aktive Beiträge zur Digitalisierung der philosophischen Fakultät an der HHU.
Verbesserung der pragmatischen Kompetenz in großen Sprachmodellen
Minderung von Verzerrungen in der automatischen Spracherkennung (ASR), der Fall des African American English (AAE)
Modelierung von unregelmäßigen morphologischen Mustern mit TransformernComputergestützter Ansatz zum Code-Switching in Internetforen
Computergestützte Analyse der spanischen Dialektvariation
Phonologische Nachbarn im Mandarin-Chinesisch
Untersuchung der Ursachen von Fehlern in der automatischen Spracherkennung (ASR) bei Nicht-Muttersprachlern
Eyetracking-Studien zu Unterschieden in spezifischen Lesegewohnheiten in Mutter- und Fremdsprachen
# SLaM @HHU
# Acknowledgements

Prof. Janice Krieger, University of Florida
# VHA ALEX
University of Florida Clinical and Translational Science Institute’s (CTSI) Precision Health Initiative pilot funding opportunity

National Endowment for the Humanities’s Humanities Collections and Reference Resources Award
# SpeechTech AAE
Prof. Yong-Kyu Yoon, University of Florida
Emeritus Prof. Lori Altmann, University of Florida
Prof. Ratree Wayland, University of Florida
National Science Foundation Award
# SELMA