Modeling probabilistic reduction across domains with Naive Discriminative Learning
Abstract
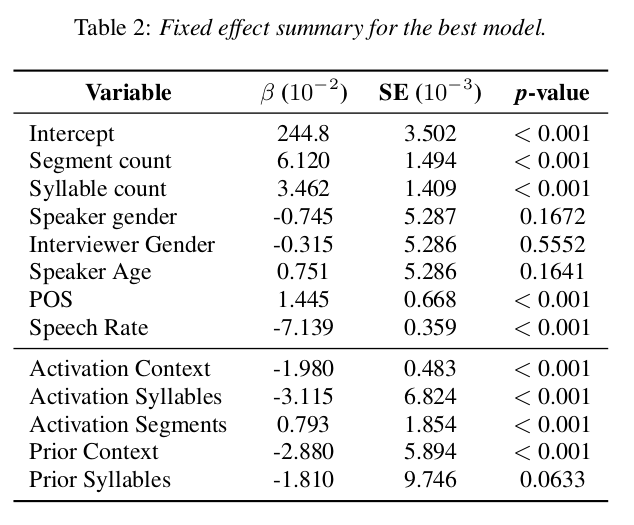
The predictability of a word modulates its acoustic duration. Such probabilistic effects can compete across linguistic domains (segments, syllables and adjacent-word contexts e.g., frequent words with infrequent syllables) and across local and aggregate contexts (e.g., a generally unpredictable word in a predictable context). This study aims to tease apart competing effects using Naive Discriminative Learning, which incorporates cue competition. The model was trained on English conversational speech from the Buckeye Corpus, using words as outcomes and segments, syllables, and adjacent words as cues. The connections between cues and outcomes were used to predict acoustic word duration. Results show that a word's duration is more strongly predicted by its syllables than its segments, and a word's predictability aggregated over all contexts is a stronger predictor than its specific local contexts. Our study presents a unified approach to modeling competition in probabilistic reduction.