Understanding Racial Disparities in Automatic Speech Recognition: The Case of Habitual "be".
Abstract
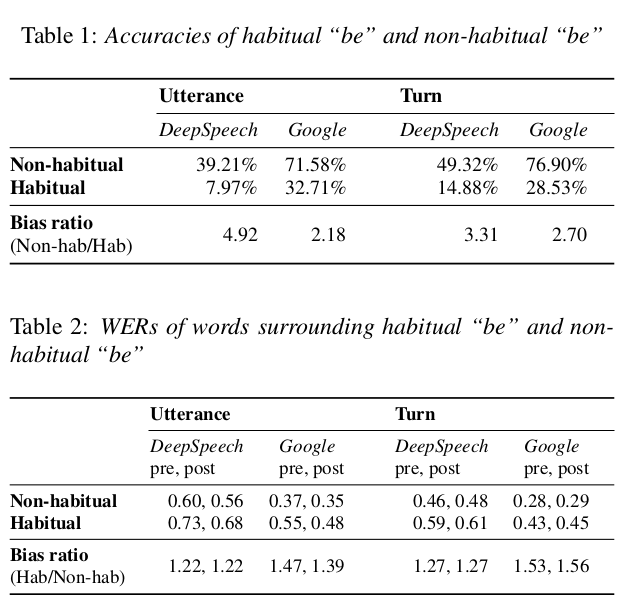
Recent research has highlighted that state-of-the-art automatic speech recognition (ASR) systems exhibit a bias against African American speakers. In this research, we investigate the underlying causes of this racially based disparity in performance, focusing on a unique morpho-syntactic feature of African American English (AAE), namely habitual “be”, an invariant form of “be” that encodes the habitual aspect. By looking at over 100 hours of spoken AAE, we evaluated two ASR systems – DeepSpeech and Google Cloud Speech – to examine how well habitual “be” and its surrounding contexts are inferred. While controlling for local language and acoustic factors such as the amount of context, noise, and speech rate, we found that habitual “be” and its surrounding words were more error prone than non-habitual “be” and its surrounding words. These findings hold both when the utterance containing “be” is processed in isolation and in conjunction with surrounding utterances within speaker turn. Our research highlights the need for equitable ASR systems to take into account dialectal differences beyond acoustic modeling.